
The Project
A terminal UI for managing llama.cpp servers. Start, stop, and monitor the server, manage versions, download GGUF models from Hugging Face, and track inference performance in real time.
Built for people who already live in the terminal. Tested in Linux.
npm install -g llama-manager
click to copy
// ABOUT
A hobby project for managing local LLM inference. Created by Patryk Bajer (bayger) and contributors.
Apache License 2.0
// IN ACTION
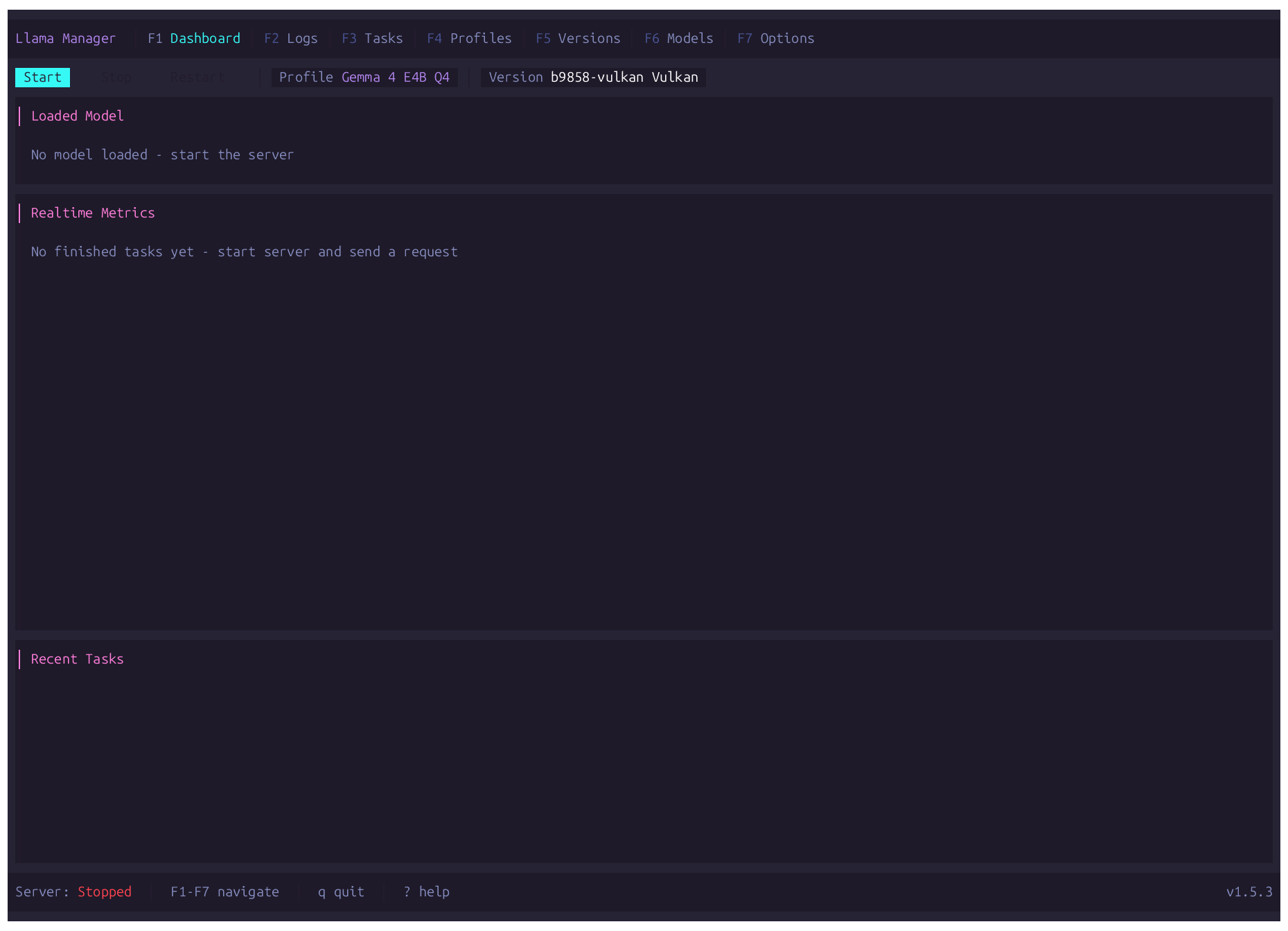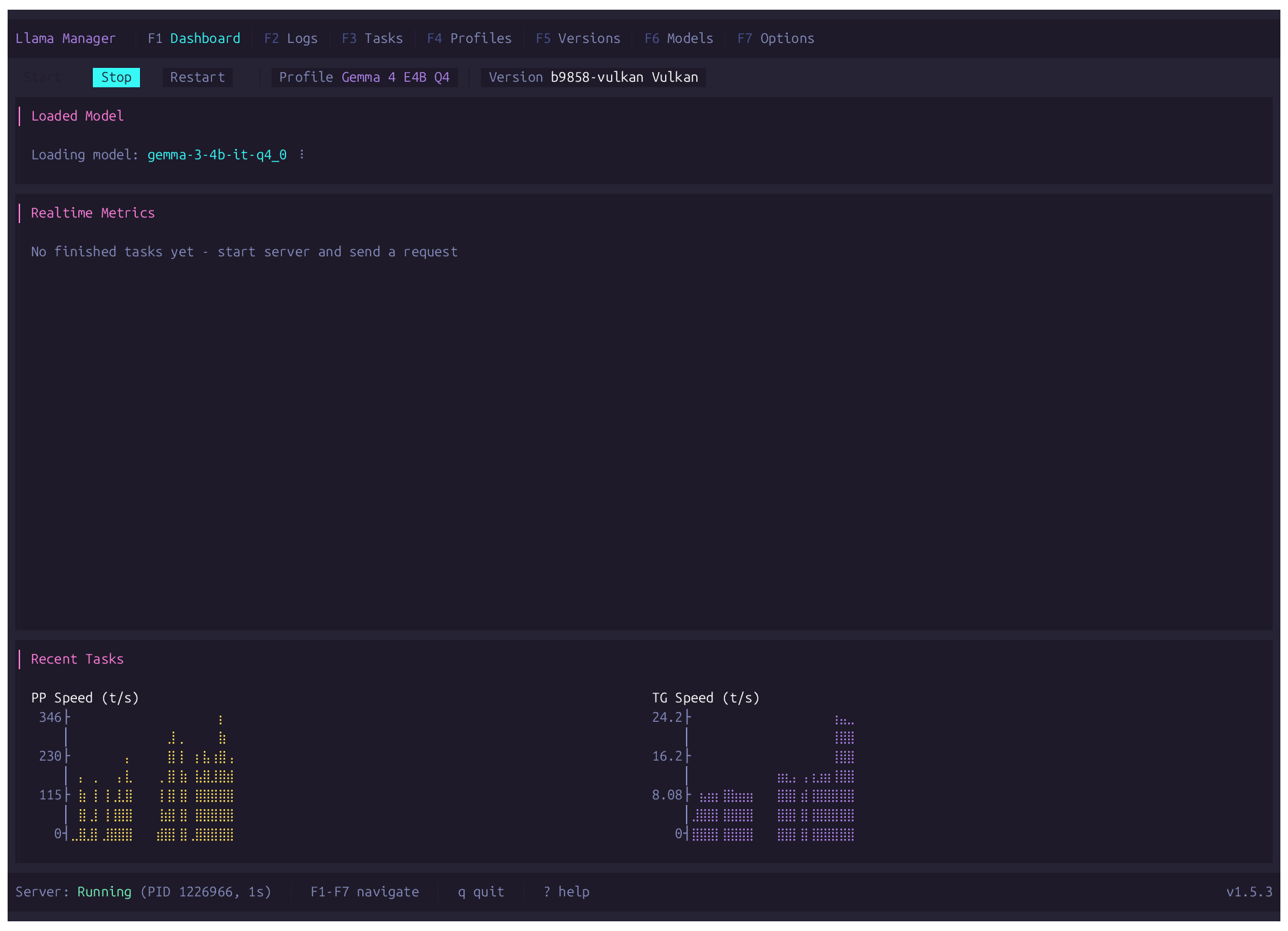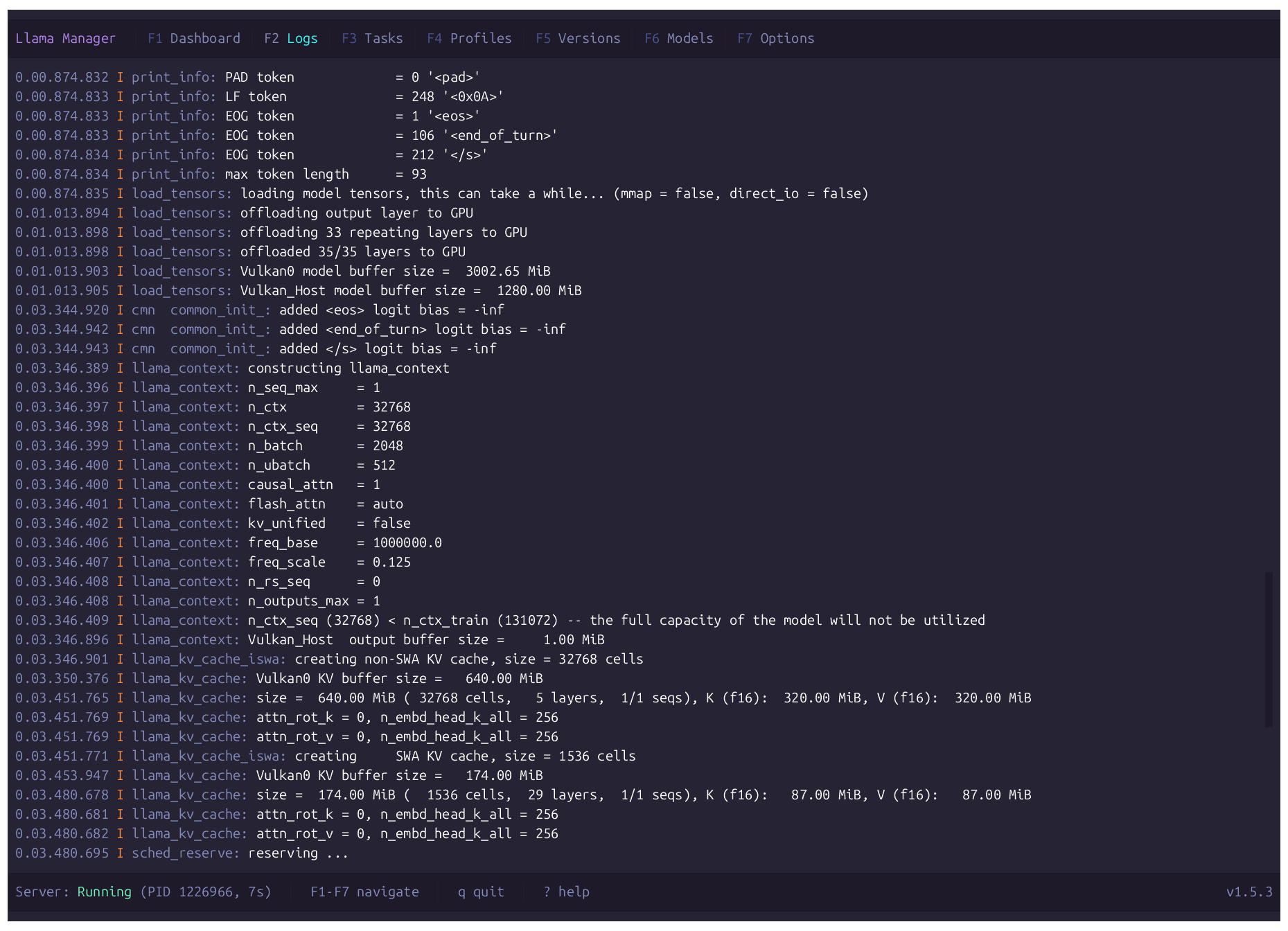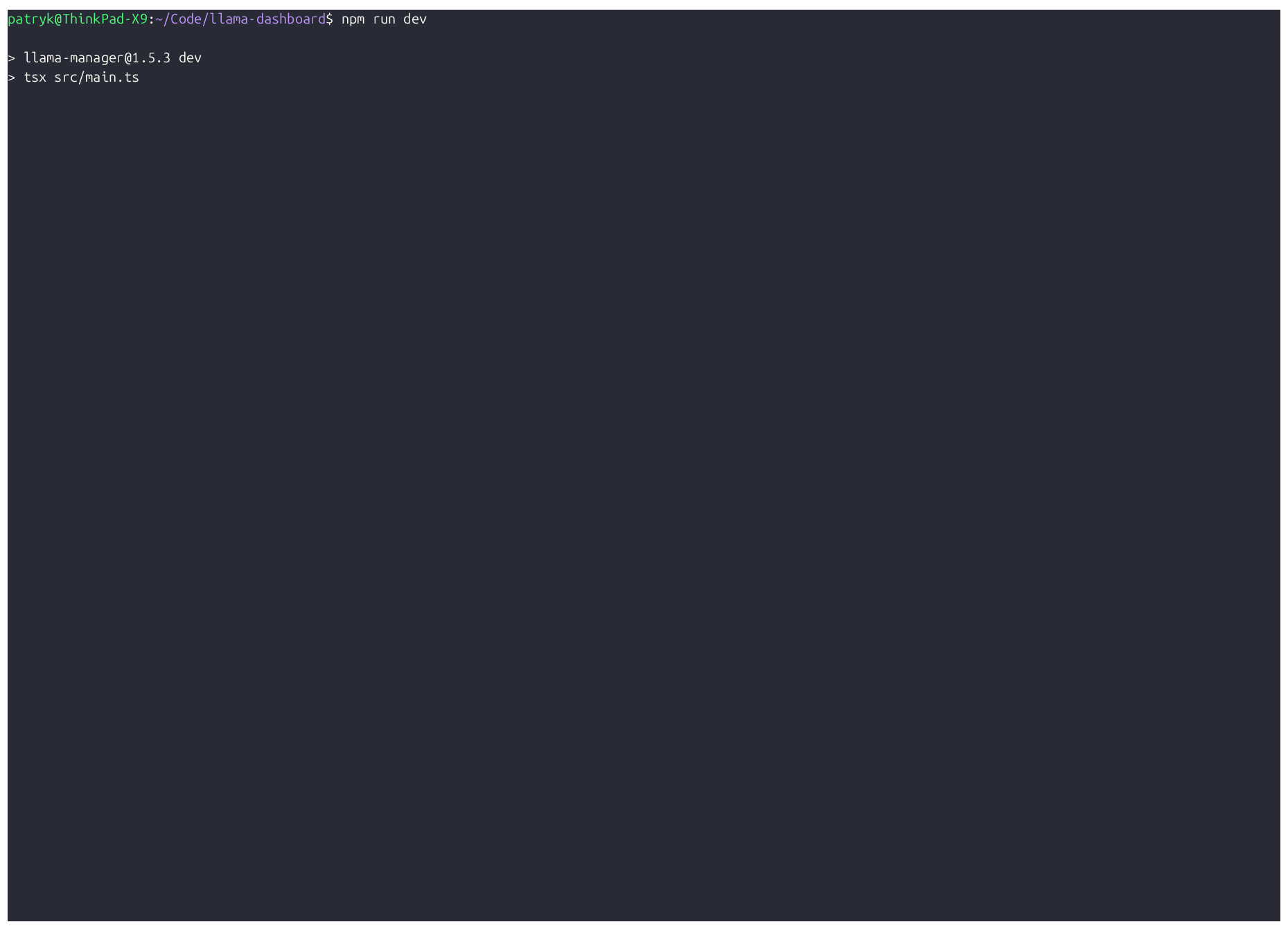
// FEATURES
Dashboard
Real-time per-slot metrics, server controls, live log viewer.
Logs
Dedicated server log viewer with structured severity coloring.
Tasks
Parsed task history with token counts, speeds, draft acceptance, SQLite persistence.
Profiles
Named server configurations with type-aware preset editors.
Versions
Install, switch, and uninstall llama.cpp builds from GitHub releases.
Models
Search Hugging Face, download GGUF models with progress tracking.
Options
Global settings: paths, poll interval, task limits, appearance, theme, HF token.
// DISCLAIMER
This project is developed in free time. New versions will be released "when they're ready". If you have an idea or something isn't working right — drop a message on the GitHub Discussions page. External PRs are closed.